Explainable AI with Streamlit SHAP Application
This app demonstrates how to use the SHAP library to explain models employing the popular `streamlit` framework for the application front end.
The application is deployed and accessed at:
Additional links are below.
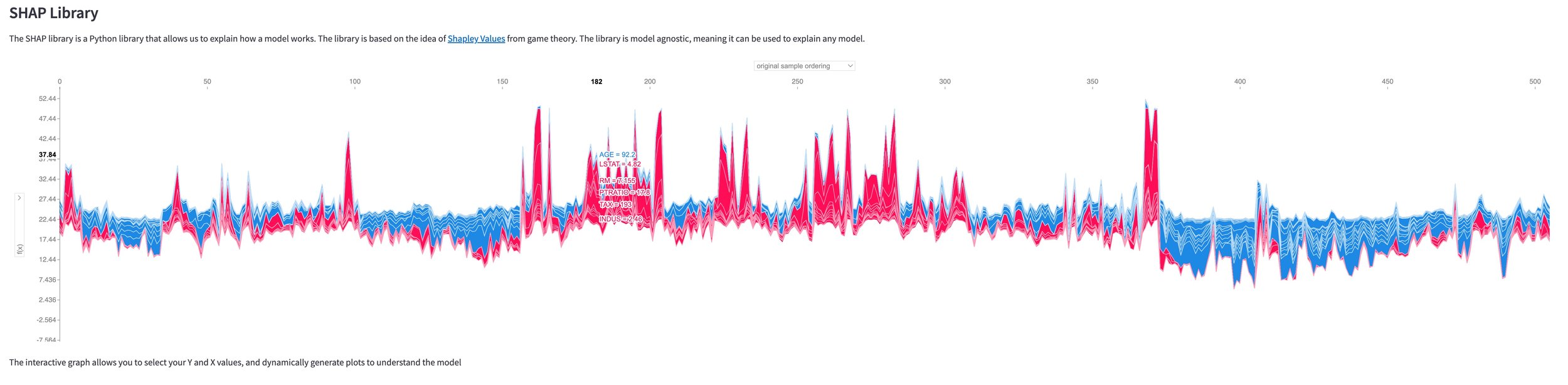
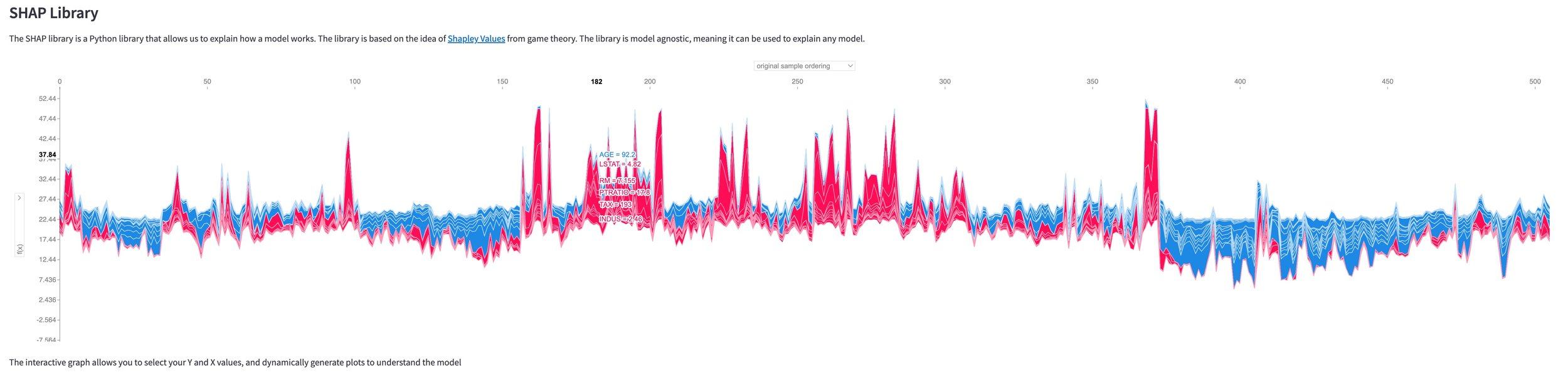
The included images are screenshots of dynamically generated images in the application, some of which you can interact with for additional information across the plots.
Shapley Values for Explanations
Shapley values are an innovative approach that enables machine learning models to assess the individual impact of each feature from a baseline level. This understanding allows us to visualize the significance and the direction of influence for every feature in a given prediction.
Regarded for their theoretical soundness in terms of consistency and accuracy, Shapley values are rapidly becoming the industry standard for explaining feature contributions in model predictions.
For linear and specific tree-based models, exact Shapley values can be computed, providing precise insights. Various approximation techniques are available for other model types, ensuring that this method is adaptable to a wide range of applications.
Project Motivation
In the dynamic field of machine learning, understanding and explaining model predictions is vital for understanding and taking actionable insights from model predictions. This project focuses on Shapley values, a concept from game theory that can be used to interpret complex models.
The primary goal of this project is to provide an intuitive introduction to Shapley values and how to use the SHAP library. Shapley values provide a robust understanding of how each feature individually contributes to a prediction, making complex models easier to understand.
Streamlit is utilized to create an interactive interface for visualizing SHAP (SHapley Additive exPlanations) prediction explanations, making the technical concepts easier to comprehend.
The project also highlights the real-world utility of prediction explanations, demonstrating that it's not merely a theoretical concept but a valuable tool for informed decision-making.
Additionally, SHAP's potential for providing a consistent feature importance measure across various models and versatility in handling diverse datasets is demonstrated.
The Interpretation of Machine Learning Models, aka Explainable AI
A Vital Component for Ensuring Transparency and Trustworthiness
In a world increasingly driven by automated decision-making, comprehending and articulating machine learning models' underlying mechanisms is paramount. This understanding, called model interpretability, enables critical insight into the actions and justifications of algorithmic systems that profoundly impact human lives.
Project Takeaways: Streamlit
Streamlit is an excellent open-source library for creating web applications that showcase machine learning and data science projects. It's easy to use, the documentation is excellent, and it integrates well with the open-source libraries used in this project. However, it may not be the best choice for scalable or enterprise-level applications. Streamlit lacks some of the more advanced customizations available in other web development frameworks. Still, my most significant concerns for using outside smaller projects and prototyping are that state management can be challenging, and performance will be an issue for large datasets or highly complex applications. A problem I ran into was that testing Streamlit apps can be challenging, as it's not a typical Python library.
Overall, I think Streamlit is a great tool to have at your disposal, and the problem it solves, getting something up and running quickly, is what it excels at.
Project Takeaways: SHAP Package
I used the SHAP (SHapley Additive exPlanations) library to interpret complex machine learning models in this project.
The experience with SHAP in the project revealed several advantages. The interpretability it provided turned previously black-box models into useful explanations, making it easy to understand the relative contributions of each feature. Its compatibility with various machine learning models and good integration with `streamlit` allowed for interactive visualizations. Moreover, SHAP's ability to uncover the influence of each feature through easy-to-generate plots is especially useful for explaining predictions to non-technical stakeholders.
However, the implementation was not without challenges. SHAP's computational intensity, especially with larger datasets and complex models, required careful optimization. While SHAP values were insightful, interpreting them can still be challenging, especially for non-technical audiences. Although informative, beautiful visualizations can become overwhelming when dealing with many features, feature selection techniques and careful design can be utilized to keep the user experience interesting.
Links
GitHub Repo: github.com/RodrigoGonzalez/streamlit-shap-app.git
Streamlit App: shap-app.streamlit.app/
Python Library: pypi.org/project/shap-app/






Features >>> Observations
Features >>> Observations: A Project Overview
The need to draw inferences from limited data with numerous variables often arises in various fields, such as business and genomics. The "Features >>> Observations" project targets this challenge, focusing on scenarios where there are more variables than observations, as encountered in areas like genetic research, image processing, text analysis, and recommender systems. This project is older, but I recently updated the code to support Python 3.8+.
Links to the code and homepage are below.
Objective and Data Overview
The project utilizes 300 variables to predict a binary target variable using only 250 observations. The anonymized data is in a CSV file in the data folder. The main goal is to engineer features that maintain predictive power without overfitting—a common issue when features outnumber observations.
Feature Selection
The training data comprises 250 rows and 300 features, making feature selection vital. Techniques such as principal component analysis (PCA), random forests for feature importance, and logistic regression model coefficients have been employed. The selected features were standardized, and in the case of PCA, 90% of the variation in the data was explained by approximately 150 features.
Tools Used
1. Python: The programming language for this project.
2. sklearn: Scikit-Learn, machine learning modules.
3. AWS: Amazon Web Services, for large instance model fitting.
4. XGBoost: Gradient boosting library.
Model Exploration
The project explored various classification algorithms, including Logistic Regression, ensemble methods (random forest, extremely randomized, bagging, adaboost, gradient boost), passive aggressive algorithms, Gaussian Naïve Bayes, Support Vector Machines, and K Nearest Neighbors.
Model Selection
The selection process involved a detailed strategy using nested cross-validation with stratified KFolds and grid searches. Different scoring methods were explored, including accuracy, ROC AUC, f1, and log-loss.
Solution and Best Models
The final solution was obtained using the entire training data set, with models like Bagging Classifier, Extremely Randomized Trees Classifier, Logistic Regression, Nu-Support Vector Classification, Random Forest, and C-Support Vector Classification. Predicted probabilities were averaged to achieve the final results.
Conclusion
This challenge provided insights into building a model with limited data and extensive features. The final model achieved an AUC of 0.97, showcasing the effectiveness of feature selection and model averaging. The project emphasizes the significance of data engineering and modeling in handling complex datasets with more features than observations.
Acknowledgments
The project acknowledges the valuable resources and algorithms provided by scikit-learn and the insightful work by Cawley, G.C.; Talbot, N.L.C. on avoiding over-fitting in model selection.
Homepage and Repository Links
- Homepage: rodrigogonzalez.github.io/more-features-less-rows/
- GitHub Repository: github.com/RodrigoGonzalez/more-features-less-rows

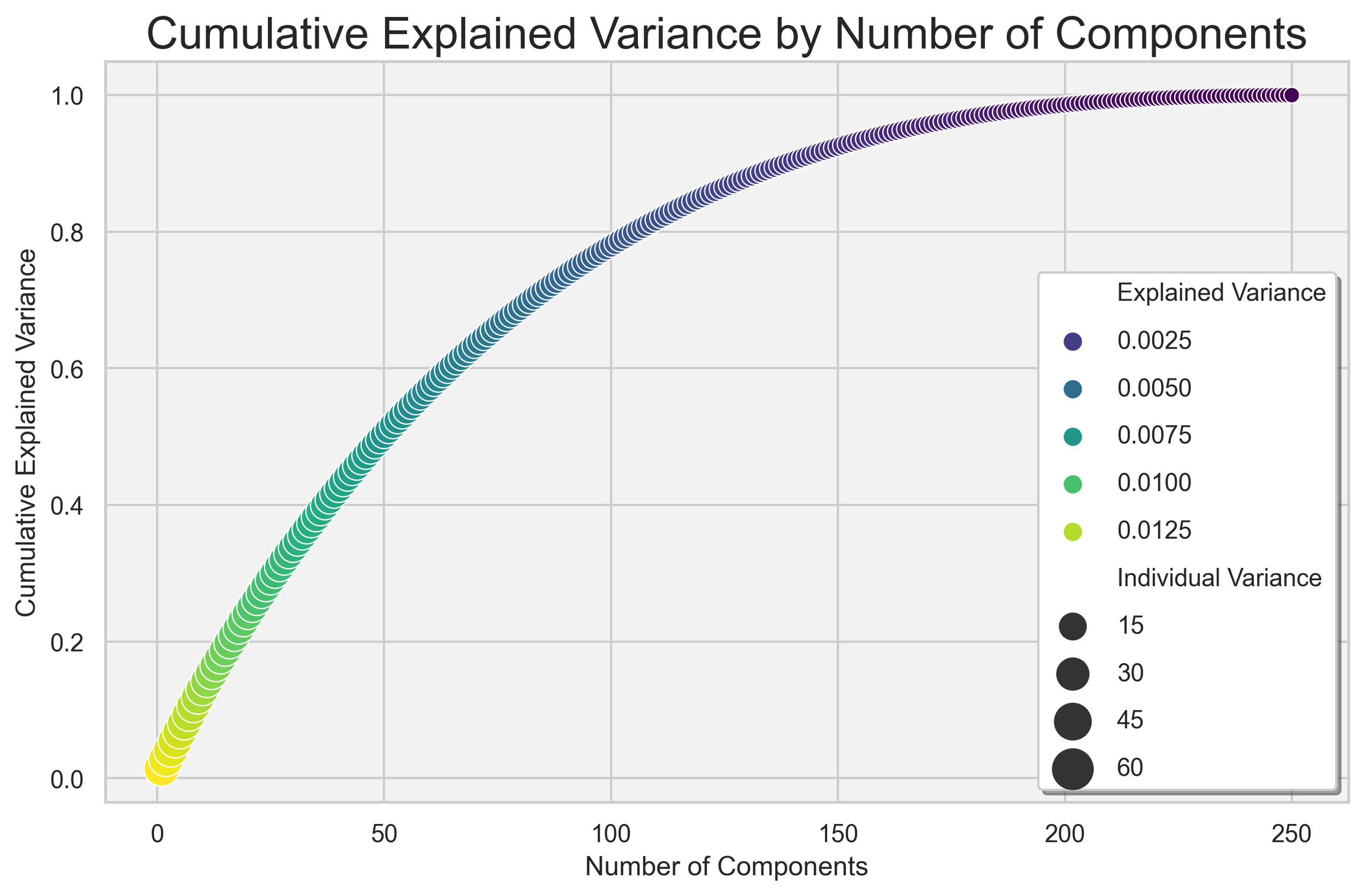
The figure illustrates the cumulative explained variance as a function of the principal components derived from Principal Component Analysis (PCA) applied to the dataset. The x-axis represents the number of principal components, whereas the y-axis indicates the cumulative explained variance. This relationship reveals how adding additional components contributes to capturing the underlying variance in the data.
flake8-custom-import-rules: Enforce Custom Import Organization in Python Projects
flake8-custom-import-rules: A Project Overview
This project is a practical `flake8` plugin I developed to address a common need in Python programming: enforcing custom import rules. While working with various Python projects, I noticed an opportunity to enhance import organization and consistency. I created a tool allowing developers to define and maintain specific import restrictions, standalone packages, and custom and project-level import rules.
Refer to the Hompage link below for a full list of supported customizations.
Motivation
The primary motivation behind the `flake8-custom-import-rules` project was to offer a simple solution to enforce custom import rules within Python projects. The plugin provides two types of import rules:
- Custom Import Rules (CIR): These enable developers to set import rules for specific packages and modules within a project.
- Project Import Rules (PIR): These allow defining and enforcing import rules at a broader project level.
These functionalities offer granular control over your import rules, carefully balancing the need for imposing restrictions with the flexibility that various projects might require. It's a tool that can adapt to the specific needs of most projects. Still, it also encourages you to think critically about the software architecture and the trade-offs and potential impacts of implementing these restrictions.
Real-World Applications
In the increasingly complex and sophisticated world of software development, the quest for clean, readable, and maintainable code is paramount. flake8-custom-import-rules not only enforces custom import rules but also promotes a modular architecture that simplifies understanding, testing, and debugging. This focus on clean and organized code isn't just about aesthetics; it's about fostering an environment where developers can work efficiently, and new team members can be onboarded swiftly.
It's particularly useful for teams working on larger projects where consistency in coding standards is essential. The plugin's emphasis on preventing unwanted dependencies and delineating clear separations between packages resonates with the modern drive for lean and efficient coding. Managing lightweight packages and maintaining a consistent import organization is a practical approach for developers striving to keep their projects free from unnecessary complexity. This practice aligns with promoting sound coding principles such as separation of concerns and encapsulation, contributing to a more streamlined and efficient codebase.
Challenges and Considerations
While developing this project, I had to consider balancing providing granular control and keeping the tool accessible and easy to use by creating a plugin that could be beneficial without imposing unnecessary restrictions or complexity.
One of the challenges was ensuring that the tool would be adaptable to different project needs. It's designed to provide options without enforcing a one-size-fits-all approach, recognizing that different projects might require varying control over import rules.
Project Takeaway
The `flake8-custom-import-rules` project represents a modest but meaningful contribution to enhancing import organization within Python projects. It's not intended to revolutionize how developers work with Python but to offer a convenient and straightforward way to enforce custom import rules.
I see this project as a testament to my ability to identify a practical need within the software development community and create a solution that addresses that need. It showcases my attention to detail and commitment to creating tools with a clear purpose.
Homepage: rodrigogonzalez.github.io/flake8-custom-import-rules/
GitHub Repository: github.com/RodrigoGonzalez/flake8-custom-import-rules
PyPi Distribution: pypi.org/project/flake8-custom-import-rules/

The diagram shows dependencies between the internal modules of the project.

MkDocs Configuration Validator: check-mkdocs
check-mkdocs: A Tool for MkDocs Configuration
Project Overview
The check-mkdocs project was developed as a practical solution for those working with MkDocs. It's a simple tool designed to address common challenges in MkDocs configuration without overcomplicating the process.
Links below.
MkDocs
MkDocs is a fast, simple, gorgeous static site generator that builds project documentation. Documentation source files are written in Markdown and configured with a single YAML configuration file.
Homepage: https://www.mkdocs.org/
Project Objective: Simplifying Validation
The complexity of configuring MkDocs, mainly when dealing with various plugins and themes, prompted the need for a tool that could take the guesswork out of the process. check-mkdocs was developed to validate the MkDocs configuration file and check for common issues, providing informative error messages to identify and fix problems quickly.
Configuring MkDocs can be tricky, especially when dealing with different plugins and themes. check-mkdocs offers a straightforward way to validate the MkDocs configuration file (default mkdocs.yml) and identify common issues. If there's an error, the tool provides a clear error message to assist in fixing the problem.
Additional Features
While its primary function is validation, check-mkdocs also includes some additional features. It can build the MkDocs project documentation using mkdocs build and check the built documentation via mkdocs serve. An optional --generate-build argument allows for a simple build of the MkDocs documentation.
Installation and Usage
Installing check-mkdocs is uncomplicated, with options to install via pip or locally with Poetry. Instructions are provided for both methods, and the tool can be easily integrated into a .pre-commit-config.yaml for those who wish to use it as a pre-commit hook.
A Practical Tool for MkDocs Users
The check-mkdocs project is a modest but useful tool for anyone working with MkDocs. It's not intended to revolutionize how you work with MkDocs but rather simplify specific tasks and provide a convenient way to validate configurations. It's a practical addition to the toolkit of developers and teams working with MkDocs.
Looking ahead, there is potential for expanding its functionalities and adapting it to new challenges within the MkDocs ecosystem. Continuous feedback and collaboration with the community will be key to steering this project towards further success.
GitHub Repo: https://github.com/RodrigoGonzalez/check-mkdocs
Homepage: https://rodrigogonzalez.github.io/check-mkdocs/
PyPi Distribution: https://pypi.org/project/check-mkdocs/

Predicting Box Office Results
The movie industry is a multi-billion dollar industry, generating approximately $40 billion of revenue annually worldwide. However, investing in the production of a feature length film is a highly risky endeavor and studios rely on only a handful of extremely expensive movies every year to make sure they remain profitable. Over the last decade, 80% of the industry’s profits was generated from just 6% of the films released; and 78% of movies have lost money of the same time period.
According to Jack Valenti, President and CEO of the Motion Picture Association of America (MPAA):
“No one can tell you how a movie is going to do in the marketplace. Not until the film opens in darkened theatre and sparks fly up between the screen and the audience.”
BoxOffice predicts movie box office revenues of feature length films to identify stock market opportunities in media properties. The tool is based on critic reviews, film characteristics, production budget, and what studio and players are involved. Producing a movie is a highly risky endeavor and studios rely on only a handful of extremely expensive movies every year to make sure they remain profitable. Box office hits and misses correspond to short-term changes in stock prices of media properties.
Project utilizes web scraping, natural language processing, and feature selection to identify factors that best predict box office success using machine learning techniques (Ensemble Methods including Random Forest & Boosting, along with a Recurrent Neural Network for sentiment analysis and Clustering Methods for binning individual features) and big data analytics
Box-office is a revenue predicting tool for feature length films using film production information and critic reviews. Web application coming soon!


lendable score
I am currently developing an innovative credit scoring platform using my own proprietary algorithms for small business lending. The software captures/analyzes big data from government, markets, and businesses, and then generates credit decisions in real time using machine learning techniques (neural networks, ensemble methods). As a result, these credit models look deep into health of small businesses, prioritizing cash flows and overall business performance, rather than the owner's personal credit history when making credit decisions
Existing lenders fail to address ease of application, customer service and turnaround time. Traditional loan applicants meet with a loan officer toting income tax records, personal finance records and other paperwork. Instead, applicants upload 90 days' worth of existing bank statements; the software imports personal and business credit profiles as well as scanning publicly available records for relevant information, using data points that include the health of an applicant's industry and region, social media data, and other public data.


Economic Feasibility of Solar Powered Methanol Production
Methanol Production Powered by Solar Power
The purpose of this project is to design and analyze the economic feasibility of constructing a methanol production facility that is powered by solar-thermal energy. The solar process used has an advantage over other technologies in that it does not produce tar byproducts, which are costly to remove in non-solar-thermal processes, additionally this process is much more environmentally friendly, compared to the current practice of using fossil fuels for energy uses.
This project uses a variety of computational methods for calculating the design, instrumentation and process controls of the chemical processes and reactions; costing & sizing of the equipment; solar reactor energy requirements and reactor design; using multivariate data analysis & chemical process optimization software. Economic and financial models for the creation of projections, expected trends and forecasts. The use of industry comparisons, ratio analysis, scenario/sensitivity and IRR returns analysis, were used to determine overall profitability over a 16-year period.
The project’s objective is an annual production of 56 million gallons of fuel grade methanol. Seventy acres of 4000 concentrated sun heliostats with a secondary radiation recovery mirror will provide an estimated 553GW-hr annually to the solar reactor.
The economic feasibility was analyzed over a 16-year period, which includes one year for plant construction. Total permanent investment (TPI) of capital into the project is approximately $294 MM with a working capital requirement of $31.58 MM. In order to achieve a 12.5% investor’s rate of return (IRR) the selling price of methanol is calculated to be $1.56/gal. Returns on investment (ROI) and corresponding payback period are 15.4% and 6.5 years respectively. The net present value (NPV) at the end of the first year is $203.02 MM. Given a market price of $1.13/gallon, the process is not economically viable given the current economic conditions.
ACKNOWLEDGEMENTS: DR. ALAN WEIMER of the University of Colorado assisted with the solar reactor and chemical process modeling




High Temperature Wire Design & Economic Feasibility
In this project a scale up study and profitability analysis is conducted for the manufacture of high temperature wire. High temperature wire has numerous applications such as in geothermal environments and is generally used in motors, furnaces, ovens, and high intensity lights.
The economic scale up study is carried out through three plant capacities: pilot (50,000 feet per year), pre-production (500,000 feet per year), and production (1-25 million feet per year). The smallest three capacities are completed in the first few years of plant operation, building up to the largest scale by the third year. The plant will be housed in a pre-existing facility in Atlanta, Georgia, and profitability analyses have been performed to determine the selling cost per foot of wire after incorporating material cost, utility use, equipment requirements, and other miscellaneous costs and investments.
Based on the analysis, the plant should run eight hours per day, seven days per week. This schedule necessitates sixteen production lines of equipment to meet the demand of 25M feet per year. The economic feasibility was studied over a 20-year period which includes one year for plant design and two years for the smaller scale productions. Total permanent investment of capital into the project is approximately $3.6M with a working capital $299K requirement. In order to achieve a 16% investor’s rate of return, the selling price of the insulated wire is $0.22 per foot. Returns on investment and corresponding payback period are 19.8% and 5.0 years, respectively. The net present value at the end of each year is $4.66M. The higher initial capital investment required for a shorter work day is compensated over time and results in a higher return on investment.